
具身智能网络架构实战:从“能用就行”到“逻辑一张网”的架构升级
发布日期:2026-04-28浏览: 327

在与具身智能客户的早期接触中,一个比较典型的现象是:
这类项目刚起步的时候,网络一般都不复杂。
研发能访问云、代码能同步、设备能回传数据,就算是“可用”。很多连接是临时搭的:有人用 VPN,有人走公网,有的地方上了专线,但整体没有统一规划。
在机器人数量还不多、数据量也不大的时候,这种方式问题不明显。
但规模一上来,情况就变了。比如:
机器人从几台变成几十台
单天数据从几十 GB 变成 TB 级
云、IDC、工厂之间开始频繁交互
这时候原来那些“能用就行”的连接方式,就会开始互相影响:路径不清晰、策略不好改、问题也不好定位。
再往后走,就会变成一个典型状态:网络还能跑,但没人敢动。
因为业务已经压在上面了。
跳出传统IT视角:基于数据生命周期的网络重构
很多IT负责人习惯沿用传统企业的思维规划网络,办公网强调出口统一和安全管控,业务网强调分区隔离和稳定性。本质是在优化“确定性的系统流量”,这些在传统系统里是有效的。但在具身智能场景下,问题不在“是否稳定”,而在于数据流动本身是持续变化的。
在实际项目中,可以将具身智能业务拆成三类典型流量场景:
一、总部研发:不怕慢一点,怕卡顿
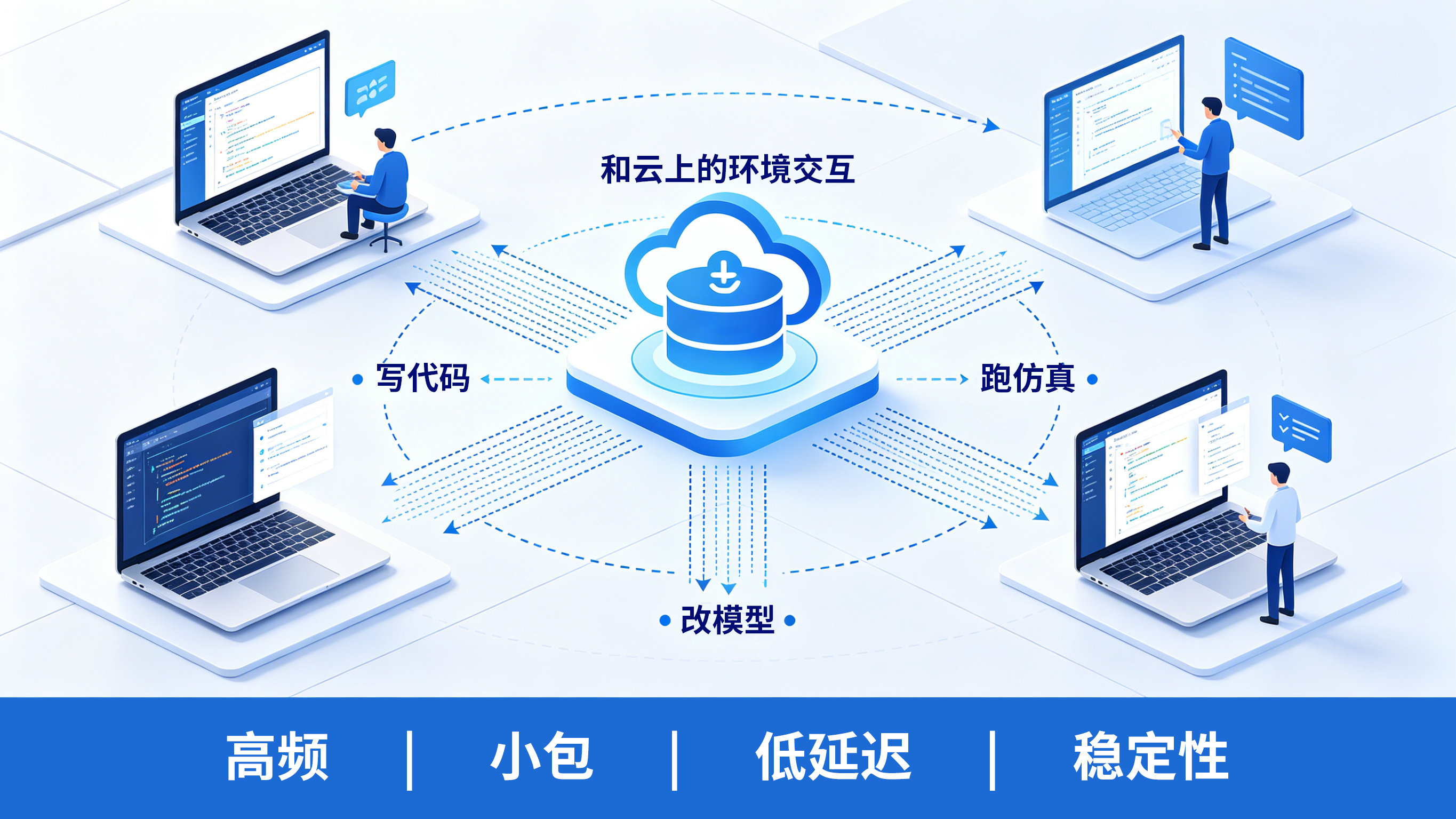
研发侧的事情比较明确:
写代码、改模型
跑仿真
和云上的环境交互
数据本身不算特别大,模型文件一般在 1–10GB,但操作很频繁:拉取、更新、回滚。
这类流量有两个特点:
频率高
单次不大
如果网络有抖动,问题会比较明显,比如:
仿真环境加载慢
Git 操作卡住
模型切换时间不可控
这些问题不会直接报错,但会拖慢节奏。时间一长,影响的是人的效率。
所以这一侧更实际的要求是:链路要稳定,体验要连续。
带宽不是最关键的指标。
二、工厂 / 实验室:数据能不能“稳稳送到”

这些数据通常不是实时用的,而是:
在边缘侧先做处理
打包
再传到云或者 IDC
所以它更像一个“持续上传”的过程,而不是实时通信。
这里如果按低延迟去设计,基本会走偏。
更关键的是这几件事:
传输过程中别频繁中断
中断了能不能续上
成本是不是能长期承受
核心不是“马上到”,而是:最后能完整到。
云与IDC交互:混合调度“来回跑”
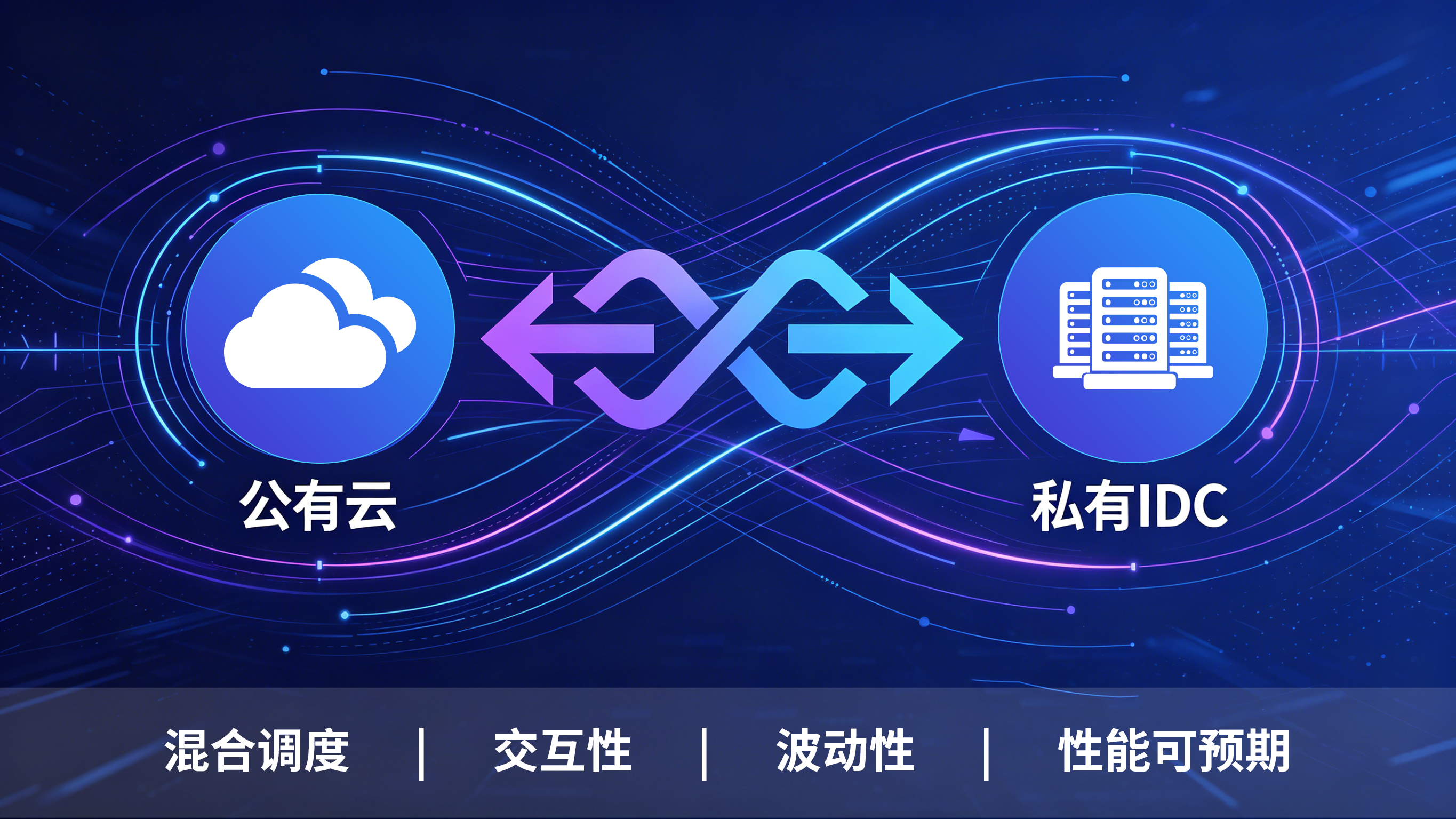
规模再大一点,基本都会变成混合架构:
云上做训练(弹性好)
IDC 做存储或者预处理(成本可控)
数据就在这两边来回跑。
这里和“单向上云”不太一样,流量会比较杂:
有一段时间带宽占得很高(比如同步数据、分发模型)
也有很多零散的小请求(调度、结果回传)
如果链路不稳定,问题不会马上爆,但会慢慢体现出来:
任务调度不均
有的算力闲着,有的在排队
这种问题很难从应用侧直接看出来,最后还是会回到网络。
“最优解”:逻辑一张网与全局可视化
当上面这些流量混在一起之后,如果底层网络还是各自独立的,就很容易变复杂。
对于尚未达到超大规模、但已有规模化预期的企业,在规划网络时建议参考以下架构原则:底层可以不同,逻辑尽量统一。
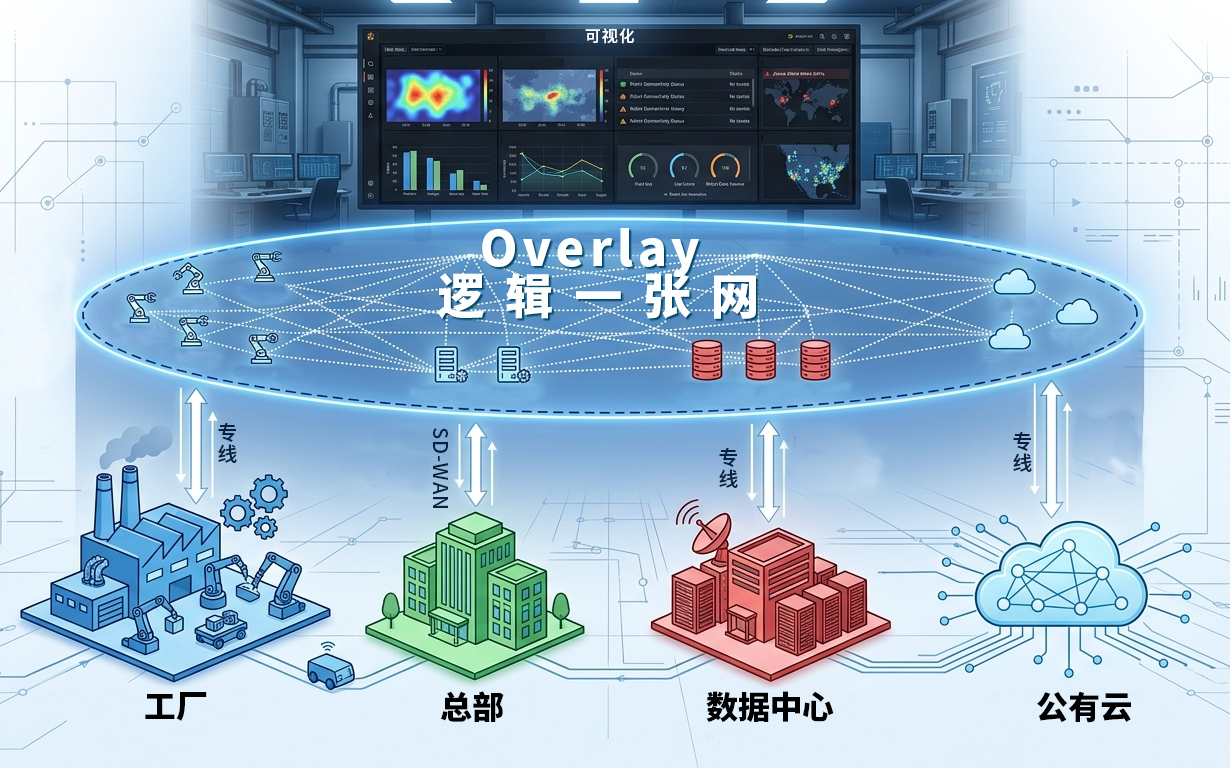
一、构建Overlay“逻辑一张网”
核心逻辑在于屏蔽底层物理差异。无论是工厂的专线、IDC的骨干网,还是总部的SD-WAN\Internet,在逻辑上都抽象成一张Full-Mesh(全网状)网络。
这样做有几个很直接的好处:
地址可以统一
不用每个环境单独规划一套,再去做 NAT 转换。
策略可以调整
比如:
模型、关键数据走质量更高的链路
日志、非关键数据走成本低一点的链路
调整策略的时候,不需要改业务。
二、必须拥有可视化
很多网络在早期的问题是:只能判断“通还是不通”。
但规模一上来,这个信息是不够的。
更有用的是:
哪一段链路在抖
延迟在哪一段变高
丢包是偶发还是持续
再往前走一步,是能不能提前看到问题,比如:
现在 20 台机器人没问题
如果变成 50 台,哪一段会先顶不住
如果只能等出问题再排查,基本就会一直被动。
一个真实的反面案例
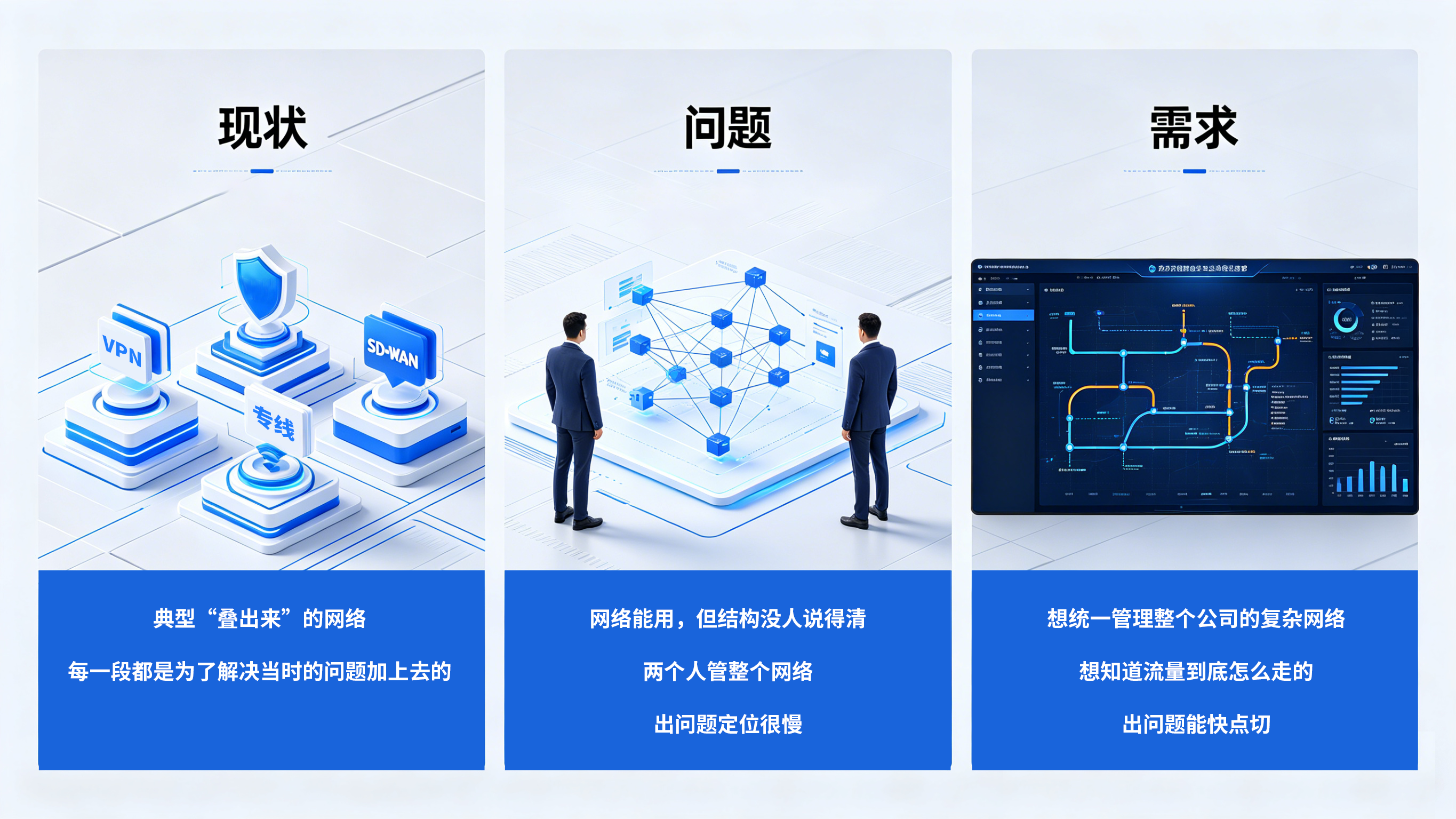 我们有个真实的大型企业客户采用多家公有云部署支撑全球业务,网络就是典型“叠出来”的:
我们有个真实的大型企业客户采用多家公有云部署支撑全球业务,网络就是典型“叠出来”的:
有的业务走专线
有的业务走 VPN
有的业务用 SD-WAN
每一段都是为了解决当时的问题加上去的。
最后的结果是:
网络能用,但结构没人说得清
两个人管整个网络
出问题定位很慢
他们提的需求也很直接:
想统一管理整个公司的复杂网络
想知道流量到底怎么走的
出问题能快点切
其实可以看出来,这已经不是“怎么建”的问题,而是“怎么管”。
但到这个阶段,再去改架构就会比较谨慎,因为已经跑着业务了。
总结:网络本质上还是在影响数据效率
具身智能看起来是在做模型、算法,但跑起来之后,很大一部分时间花在数据上:
采集
传输
处理
再训练
网络就在中间。
如果网络不稳定,或者路径不清晰,问题不会只体现在“网慢”,而是整个节奏被拉长。
所以从实际工作角度看,网络更像是在解决三件事:
数据怎么稳定地流动
成本能不能压住
出问题能不能快速定位
这些事情,如果一开始没有考虑,后面补起来成本会比较高。
相比之下,早点把结构想清楚,反而更省事一些。
SD-WAN是否将终结IPSec VPN?
AI创业公司的算力困境,远比你想象的更复杂
迎接混合云下半场:Hybrid WAN赋能智能化的未来之路
如何破解AI推理延迟难题:构建敏捷多云算力网络
领先AI企业经验谈:探究AI分布式推理网络架构实践
各大云厂商BGP路由条目限制全解析 —— 你的100条路由够用吗?
“连接器”国家助力出海:打破企业数据孤岛,构建高效全球网络
AI创业公司如何突破算力瓶颈,实现高效发展?
告别黑盒网络,运维的“AI”助手——流量分析
连锁药店网络优化策略:一站式融合方案提升竞争力
